xPath crashcourse
XPath, short for XML Path Language, is a query language used for selecting nodes from an XML or HTML document. In the context of Midesk, XPath enables you to extract structured data from web pages, providing valuable insights for your competitive monitoring efforts.
Understanding the Basics
Webpage source code: Every webpage has a source code that consists of HTML elements, attributes, and content.
Document Object Model (DOM): The DOM is a hierarchical structure representing the source code of a webpage, visually resembling a tree. You can view the DOM for any webpage by right-clicking anywhere on a page and selecting ”Inspect Element.”
XPath: XPath is a powerful language used to navigate and extract specific nodes from the DOM, making it possible to retrieve structured data from web pages.
Getting Started with XPath
To use XPath in the Midesk system, follow these steps:
Inspect the DOM: Right-click on any element within a webpage you want to use for monitoring and click “Inspect Element” to open the browser’s developer tools and display the DOM.
Copy the XPath: In the developer tools, right-click on the desired HTML element, hover over “Copy,” and select “Copy XPath.” This action will copy the XPath expression to your clipboard.
Example of an XPath expression:
//*[@id="text"]/h1Use XPath in Midesk: Open a monitoring task -> add / select a processing step, select xPath method and paste the copied XPath expression into the field “Extraction pattern” as in the screenshot below.
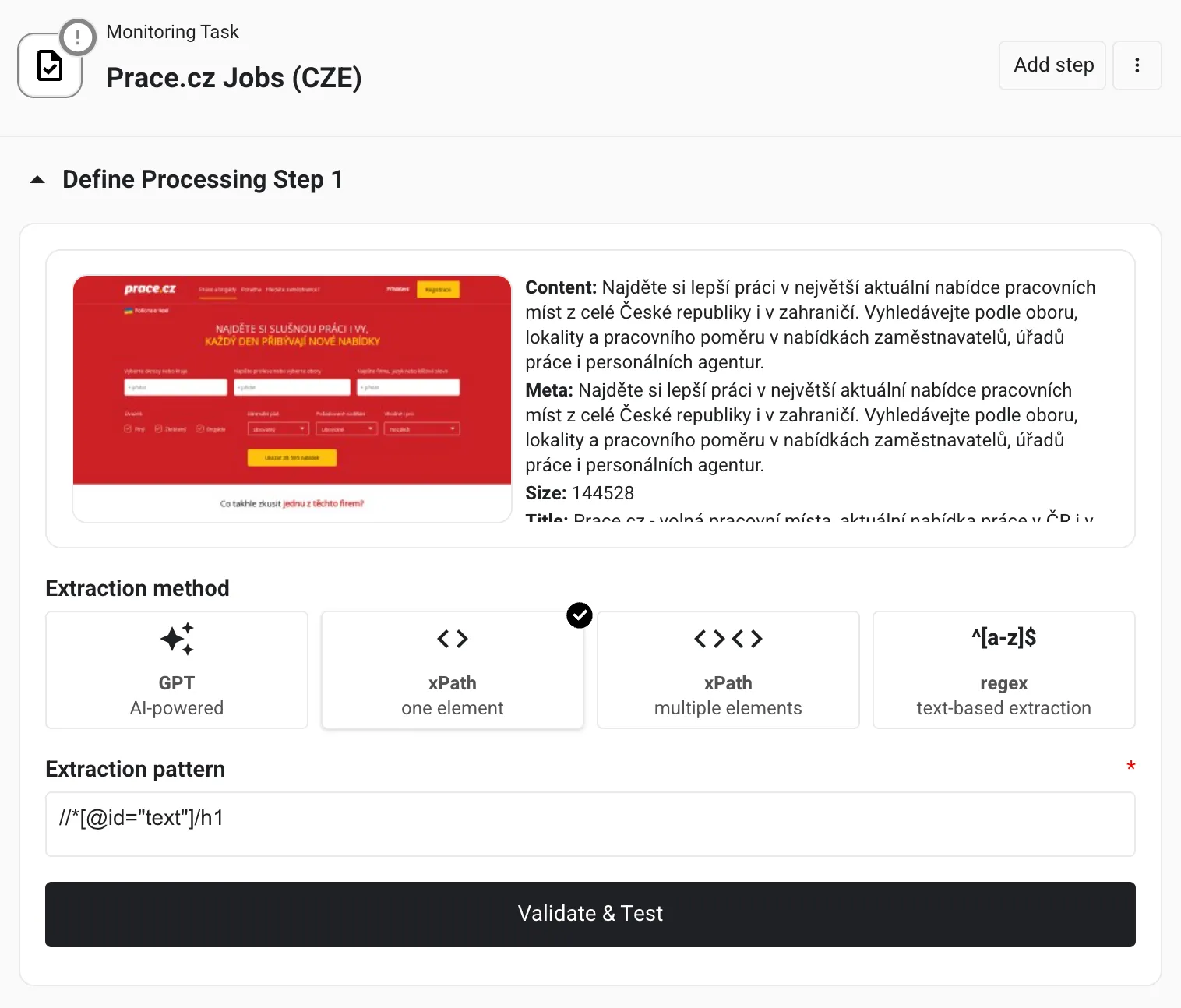
Tips and Best Practices
XPath syntax: Familiarize yourself with the basic XPath syntax and functions to create more precise and efficient queries. A helpful cheat sheet can be found at https://devhints.io/xpath.
Robust vs. brittle XPath: Some XPath expressions can be brittle, breaking easily if there are changes to the webpage’s structure. Aim to create robust XPath expressions that can withstand minor changes to the DOM.
Test your XPath: Before using an XPath expression in Midesk, test it in your browser’s developer tools to ensure it accurately targets the desired element.
Example
Suppose you want to extract the title of a blog post from a webpage with the following HTML structure:
Inspect the DOM: Right-click on the blog post title and select “Inspect Element.”
Copy the XPath: In the developer tools, right-click the <h1> element containing the title, hover over “Copy,” and select “Copy XPath.” The copied XPath expression should look like this:
//*[@id="content"]/h1Use XPath in Midesk: Paste the XPath expression into the appropriate field in the Midesk system to extract the blog post title.