Processing steps
Overview
Processing steps are specific methods used to extract data within Monitoring Tasks, such as xPath, JSON, and Regex. Each monitoring task may have multiple processing steps, determining how to extract data from different sources. In this section, you’ll learn how to set up, manage, and modify processing steps to ensure precise and efficient data extraction, ultimately improving your competitive intelligence strategy.
In detail
Processing steps are functions that run every single time you scrape a website/API. They help you bend and transform monitoring results into standardized data.
In order to build a Market Intelligence monitoring pipeline, Midesk offers many ways to processes and extract to exact results you want.
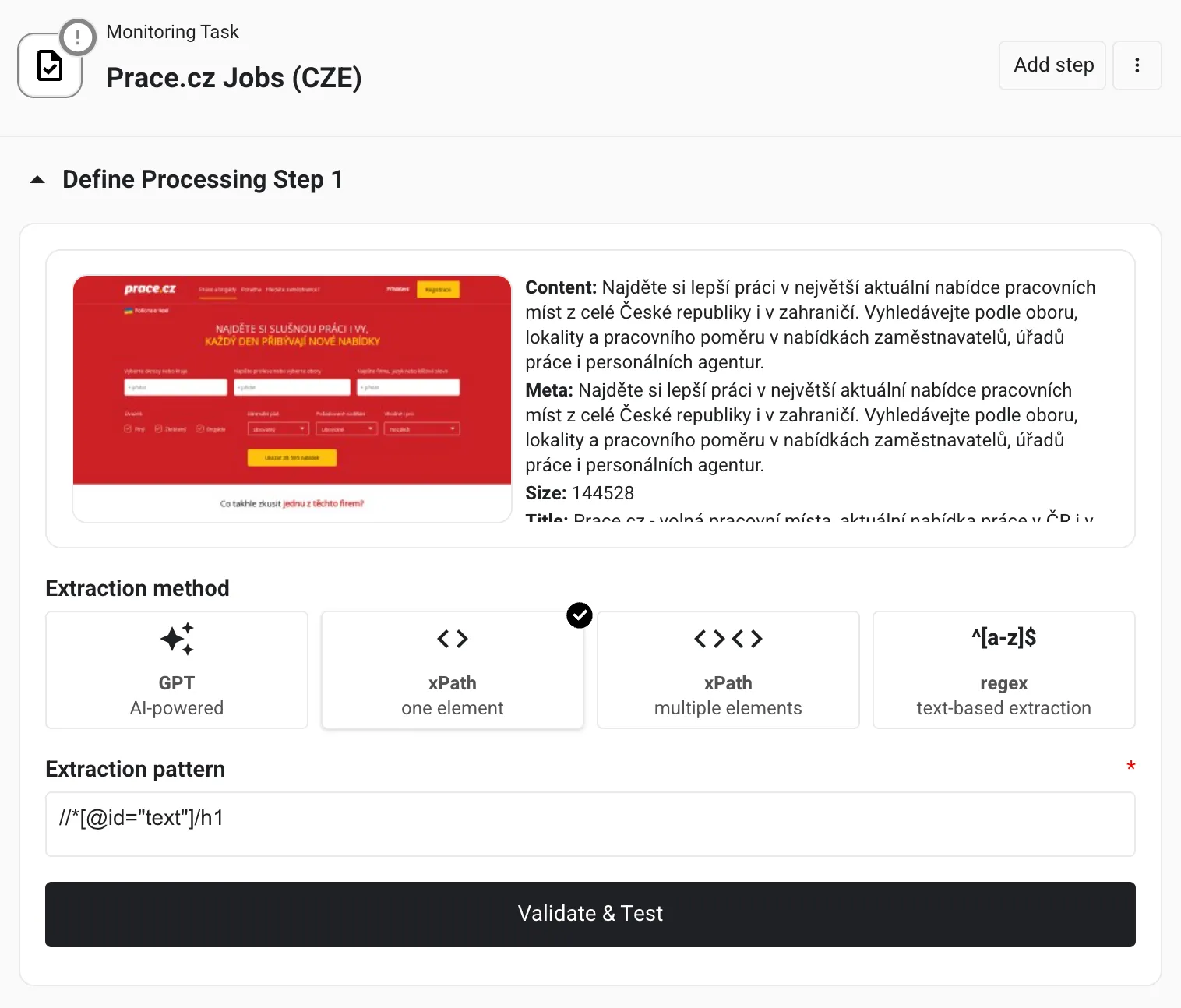
A default view of the user interface with a processing step that extracts a title from a webpage.
There are in three very flexible methods that can help you: xPath and JSON. The use depends on the type of data you work with. If you work with HTML elements and websites, xPath is your friend. If you work with API or object structures, JSON method will help you tremendously.
Processing Methods
Midesk offers multiple way how to process, mold and extract the exact content you’d like to. There are three key methods you can use:
xPath
Use case: Structured HTML or XML processing
Description: XPath (XML Path Language) is a query language for selecting nodes from an XML document. In addition, XPath may be used to compute values (e.g., strings, numbers, or Boolean values) from the content of an XML document. XPath was defined by the World Wide Web Consortium (W3C).
You can use the xPath method to not only process traditional websites but also XML files and RSS.
JSON
Use case: Structured API & Objects processing
Description: JSON is an open standard file format, and data interchange format, that uses human-readable text to store and transmit data objects consisting of attribute—value pairs and array data types. It is a very common data format, with a diverse range of applications, such as serving as a replacement for XML in AJAX
Regex
Use case: Unstructured text processing
Description: A regular expression (shortened as regex or regexp; also referred to as rational expression) is a sequence of characters that specifies a search pattern. Usually such patterns are used by string-searching algorithms for “find” or “find and replace” operations on strings, or for input validation.
JSON Processing Functions
Transform
The notation of transform uses so-called “dot notation”. A dot notation allows you to represent nested keys with a text notation. Each key is separated by a dot . sign.
Notation for simple elements
{"city": "Hamburg", "county": "Germany"}Location: ${city} (${country})[
"Location: Hamburg (Germany)"
]Notation for chunked elements
[
{
"title": "Company",
"text": "Strategy"
},
{
"title": "Other company",
"text": "Market Intelligence"
}
]Location: ${ title } SOME TEXT ${ text }[
"Location: Germany SOME TEXT Strategy",
"Location: Other company SOME TEXT Market Intelligence"
]Pipes
The transform method supports many pipes that help you work with the text. Pipes can be chained and perform operations from left to right. Pipes are denoted by a pipe | sign. Pipes may have one or two additional parameters which are separated by a colon : sign.
How to apply pipes
{
"city": "Hamburg",
"county": "Germany"
}Location: ${ city | upper } (${ country | upper })[
"Location: HAMBURG (GERMANY)"
]List of Pipes
after
The after pipe returns everything after the given value in a string. The entire string will be returned if the value does not exist within the string.
some 123 Some random 123 text 123 <a><i>Text in a span</i></a> - text $ Abcafter : '123'Some random 123 text 123 <a><i>Text in a span</i></a> - text $ AbcafterLast
The afterLast pipe returns everything after the last occurrence of the given value in a string. The entire string will be returned if the value does not exist within the string.
some 123 Some random 123 text 123 <a><i>Text in a span</i></a> - text $ AbcafterLast : '123'<a><i>Text in a span</i></a> - text $ Abcappend
The append pipe appends the given values to the string.
some 123 Some random 123 text 123 <a><i>Text in a span</i></a> - text $ Abcappend : ' appended text'some 123 Some random 123 text 123 <a><i>Text in a span</i></a> - text $ Abc appended textascii
The ascii pipe will attempt to transliterate the string into an ASCII value.
ûěščřžýáíasciiuescrzyaibefore
The before pipe returns everything before the given value in a string.
some 123 Some random 123 text 123 <a><i>Text in a span</i></a> - text $ Abcbefore : '123'somebeforeLast
The beforeLast pipe returns everything before the last occurrence of the given value in a string.
some 123 Some random 123 text 123 <a><i>Text in a span</i></a> - text $ AbcbeforeLast : '123'some 123 Some random 123 textbetween
The between pipe returns the portion of a string between two values.
some 123 Some random 123 text 123 <a><i>Text in a span</i></a> - text $ AbcbeforeLast : 'random' : '123'some 123 SomebetweenFirst
The betweenFirst pipe returns the smallest possible portion of a string between two values.
some 123 Some random 123 text 123 <a><i>Text in a span</i></a> - text $ AbcbetweenFirst : '123' : '123'Some randomcamel
The camel pipe converts the given string to camelCase.
some 123 Some random 123 text 123 <a><i>Text in a span</i></a> - text $ Abccamelsome123SomeRandom123Text123<a><i>TextInASpan</i></a>Text$Abccast
The cast pipe transforms provided value into one of the following types: text, date, number, boolean.
Wed Sep 14 2022 19:29:50 GMT+0000cast : 'text'Wed Sep 14 2022 19:29:50 GMT+0000Wed Sep 14 2022 19:29:50 GMT+0000cast : 'number'0Wed Sep 14 2022 19:29:50 GMT+0000cast : 'boolean'1Wed Sep 14 2022 19:29:50 GMT+0000cast : 'date'2022-09-14contains
The contains pipe determines if the given string contains the given value. This method is case sensitive:
soome text is herecontains : 'text'1some text is herecontains : 'NOT THERE'0decode
The decode pipe converts HTML entities to their corresponding characters.
<a href='http://midesk.co'></a>decode<a href='http://midesk.co'></a>endsWith
The endsWith pipe determines if the given string ends with the given value.
some/path/endsWith : '/'1some/pathendsWith : '/'0finish
The finish pipe adds a single instance of the given value to a string if it does not already end with that value.
some/path/finish : '/'some/path/some/pathfinish : '/'some/path/is
The is pipe determines if a given string matches a given pattern. Asterisks may be used as wildcard values.
randomis : 'ran*'1randomis : 'random'1randomis : 'nomatch'0isAscii
The isAscii pipe determines if a given string is an ASCII string.
MideskisAscii1ČeskoisAscii0isUuid
The isUuid pipe determines if the given string is a valid UUID.
4a601006-5d47-44ac-a316-bd49447fac61isUuid1mideskisUuid0kebab
The kebab pipe converts the given string to kebab-case.
Midesk is greatkebabmidesk-is-greatlcfirst
The lcfirst pipe returns the given string with the first character lowercased.
Midesk Is Greatlcfirstmidesk Is Greatlength
The length pipe returns the length of the given string.
some 123 Some random 123 text 123 <a><i>Text in a span</i></a> - text $ Abclength75limit
The limit pipe truncates the given string to the specified length.
some 123 Some random 123 text 123 <a><i>Text in a span</i></a> - text $ Abclimit : '5'somelower
The lower pipe converts the given string to lowercase.
some 123 Some random 123 text 123 <a><i>Text in a span</i></a> - text $ Abclowersome 123 some random 123 text 123 <a><i>text in a span</i></a> - text $ abcltrim
The ltrim pipe trims the left side of the string. This pipe is automatically applied to the end result.
some 123 Some random 123 text 123 <a><i>Text in a span</i></a> - text $ Abcltrimsome 123 Some random 123 text 123 <a><i>Text in a span</i></a> - text $ Abcmatch
The match pipe will return the portion of a string that matches a given regular expression pattern.
some 123 Some random 123 text 123 <a><i>Text in a span</i></a> - text $ Abcmatch : '/random (.*) text/'123 text 123 <a><i>Text in a span</i></a> -matchAll
The matchAll pipe will return a collection containing the portions of a string that match a given regular expression pattern.
some 123 Some random 123 text 123 <a><i>Text in a span</i></a> - text $ AbcmatchAll : '/(.*) text/'["some 123 Some random 123 text 123 <a><i>Text in a span<\/i><\/a> -"]md5
The md5 pipe uses a cryptographically broken but still widely used hash function producing a 128-bit hash value.
Mideskmd58d658da2a7bcb1d515993d51ed030c4bpadBoth
The padBoth pipe adds padding both sides of a string with another string until the final string reaches the desired length.
MideskpadBoth : '10' : '_' __Midesk__padLeft
The padLeft method adds padding the left side of a string with another string until the final string reaches the desired length.
MideskpadLeft : '10' : '_' ____MideskpadRight
The padRight method adds padding the right side of a string with another string until the final string reaches the desired length.
MideskpadRight : '10' : '_' Midesk____plural
The plural pipe converts a singular word string to its plural form. This function currently only supports the English language. You may provide an integer as a first parameter to retrieve the singular or plural form of the string:
carpluralcarscarplural:1carcarplural:20carsprepend
The prepend pipe prepends the given values onto the string.
is greatprepend : 'Midesk 'Midesk is greatremove
The remove pipe removes the given value or array of values from the string.
some 123 Some random 123 text 123 <a><i>Text in a span</i></a> - text $ Abcremove : 'e'som 123 Som random 123 txt 123 <a><i>Txt in a span</i></a> - txt $ Abcreplace
The replace method replaces a given string within the string.
some 123 Some random 123 text 123 <a><i>Text in a span</i></a> - text $ Abcreplace : '123' : 'ABC' some ABC Some random ABC text ABC <a><i>Text in a span</i></a> - text $ AbcreplaceFirst
The replaceFirst pipe replaces the first occurrence of a given value in a string.
some 123 Some random 123 text 123 <a><i>Text in a span</i></a> - text $ AbcreplaceFirst : '123' : 'ABC' some ABC Some random 123 text 123 <a><i>Text in a span</i></a> - text $ AbcreplaceLast
The replaceLast pipe replaces the last occurrence of a given value in a string.
some 123 Some random 123 text 123 <a><i>Text in a span</i></a> - text $ AbcreplaceLast : '123' : 'ABC' some 123 Some random 123 text ABC <a><i>Text in a span</i></a> - text $ AbcreplaceMatches
The replaceMatches pipe replaces all portions of a string matching a pattern with the given replacement string.
some 123 Some random 123 text 123 <a><i>Text in a span</i></a> - text $ AbcreplaceMatches : '/[^A-Za-z0-9]++/' : '' some123Somerandom123text123aiTextinaspaniatextAbcrtrim
The rtrim pipe trims the right side of the given string. This pipe is automatically applied to the end result.
Midesk rtrimMideskMidesk/rtrim : '/'Midesksingular
The singular pipe converts a string to its singular form. This function currently only supports the English language.
carssingularcarcheesesingularcheesethe cupssingularthe cupslug
The slug pipe generates a URL friendly "slug" from the given string.
some 123 Some random 123 text 123 <a><i>Text in a span</i></a> - text $ Abcslugsome-123-some-random-123-text-123-aitext-in-a-spania-text-abcsnake
The snake pipe converts the given string to snake_case.
some 123 Some random 123 text 123 <a><i>Text in a span</i></a> - text $ Abcsnakesome123_some_random123_text123<a><i>_text_in_a_span</i></a>-_text$_abcsquish
The squish pipe removes all extraneous white space from a string, including extraneous white space between words.
Midesk is greatsquishMidesk is greatstart
The start pipe adds a single instance of the given value to a string if it does not already start with that value.
/some/path/start : '/'/some/path//some/pathstart : '/'/some/pathstartsWith
The startsWith pipe determines if the given string begins with the given value.
/some/pathstartsWith : '/'1some/pathstartsWith : '/'0stripTags
The stripTags pipe strips HTML and PHP tags from the given string.
some 123 Some random 123 text 123 <a><i>Text in a span</i></a> - text $ AbcstripTagssome 123 Some random 123 text 123 Text in a span - text $ Abcstudly
The studly pipe converts the given string to StudlyCase.
some 123 Some random 123 text 123 <a><i>Text in a span</i></a> - text $ AbcstudlySome123SomeRandom123Text123<a><i>TextInASpan</i></a>Text$Abcsubstr
The substr pipe returns the portion of the string specified by the given start and length parameters.
some 123 Some random 123 text 123 <a><i>Text in a span</i></a> - text $ Abcsubstr : '10' : '5' ome rsubstrCount
The substrCount pipe returns the number of occurrences of a given value in the given string.
some 123 Some random 123 text 123 <a><i>Text in a span</i></a> - text $ AbcsubstrCount : '123'3title
The title pipe converts the given string to Title Case.
some 123 Some random 123 text 123 <a><i>Text in a span</i></a> - text $ AbctitleSome 123 Some Random 123 Text 123 <A><I>Text In A Span</I></A> - Text $ Abctrim
The trim pipe trims the given string. This pipe is automatically applied to the end result.
some 123 Some random 123 text 123 <a><i>Text in a span</i></a> - text $ Abctrimsome 123 Some random 123 text 123 <a><i>Text in a span</i></a> - text $ Abcucfirst
The ucfirst pipe returns the given string with the first character capitalized.
midesk is greatucfirstMidesk is greatupper
The upper pipe converts the given string to uppercase.
midesk is greatupperMIDESK IS GREATwordCount
The wordCount function returns the number of words that a string contains.
some 123 Some random 123 text 123 <a><i>Text in a span</i></a> - text $ AbcwordCount15xPath
xPath
some 123 Some random 123 text 123 <a><i>Text in a span</i></a> - text $ AbcxPath://iText in a span