Scrape Articles & Job Postings
Download blog posts, news articles, job postings and other content into structured data with attached metadata
With Midesk’s advanced multi-step scraping feature, you can automatically identify links in text and download the underlying content (HTML, JSON, XML, PDF) with metadata (such as title, publisher, location) with ease.
If you are looking for a solution to monitoring & scrape individual data points, such as KPIs, head to quantitative scraping.
Benefits of Automated Competitive Content Scraping
Leverage publicly available data on websites, such as competitors’ pricing pages, pages with downloadable files (e.g. investor relations), competitor job boards or any other resources, to establish a crucial information extraction pipeline for strategic planning, research projects, and daily Market & Competitive Intelligence operations.
Redistribute your content
The data is stored in your channels and can be
- displayed and interacted with,
- repackaged as newsletter, PDF or PowerPoint,
- bundled into RSS channels (incl. password protection),
- iframes or
- queued by API.
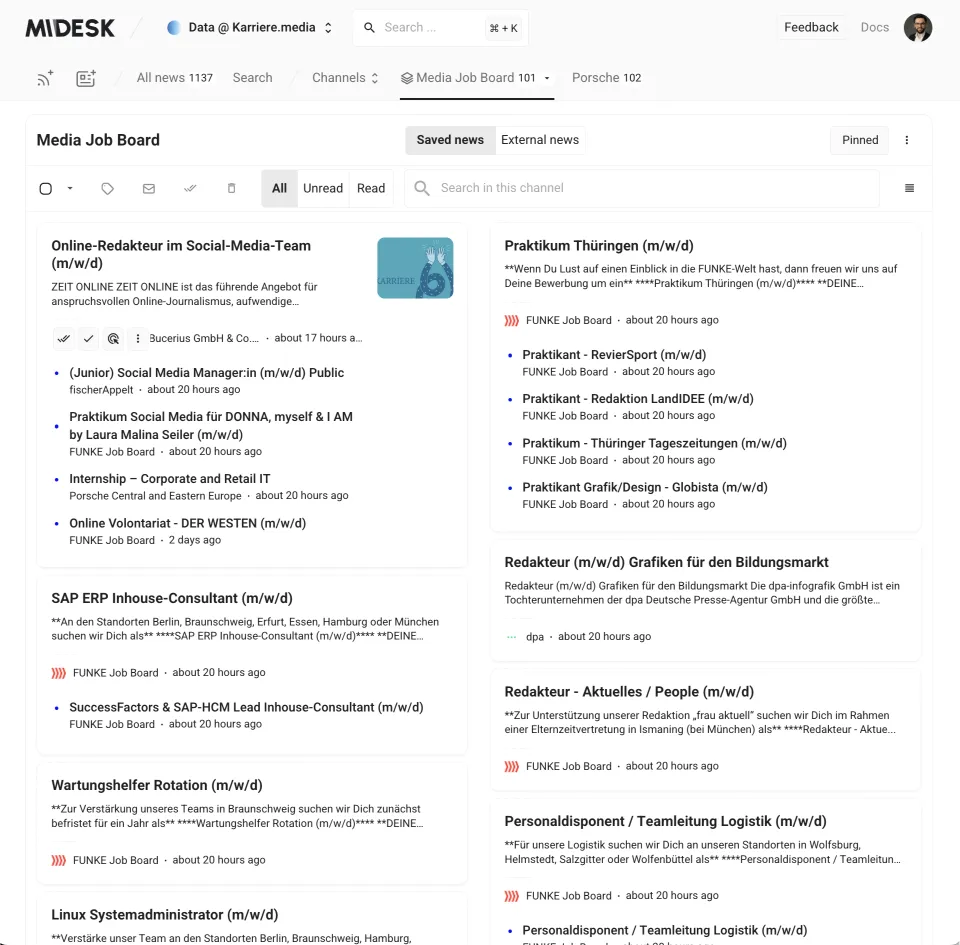
For example, you may point a monitoring job to a job board or a blog and monitor the latest entries. Once a new entry is found, you may define that such an entry shall be saved to your system, for example, to a specific News Channel.
Beyond preventing duplicates
Midesk’s Article Downloader prevents duplicate content by using AI-powered quality processing and duplicate identification, ensuring that only new entries are downloaded. The quality layers also suggest what articles seem relevant based on your past activity and exclude articles that you never download or interact with.
Distribution
Once you have downloaded the content, you can distribute it to your team members, for example, via a News Channel or Newsletter, Slack and PDF.
See our solution in action
Let's discuss your particular Market & Competitive Intelligence needs and see how Midesk can address them.